DiffSynthISMIR
Accompanying Website for Synthesizer Sound Matching with Differentiable DSP (ISMIR2021)
Summary
While synthesizers have become commonplace in music production, many users find it difficult to control the parameters of a synthesizer to create the intended sound. In order to assist the user, the sound matching task aims to estimate synthesis parameters that produce a sound closest to the query sound.
In recent years, neural networks have been employed for this task. These neural networks are trained on paired data of synthesis parameters and the corresponding output sound, optimizing a loss of synthesis parameters. However, synthesis parameters are only indirectly correlated with the audio output. Another problem is that query made by the user usually consists of real-world sounds, different from the synthesizer output used during training.
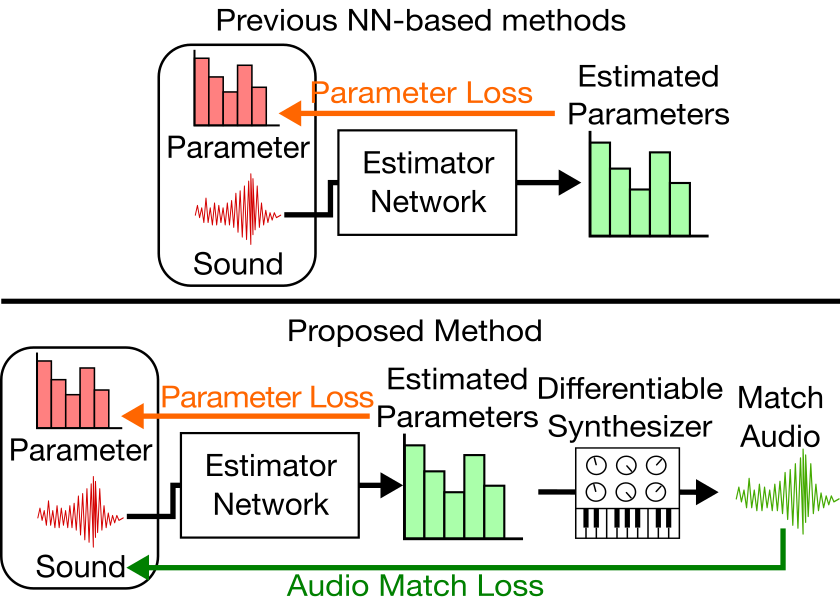
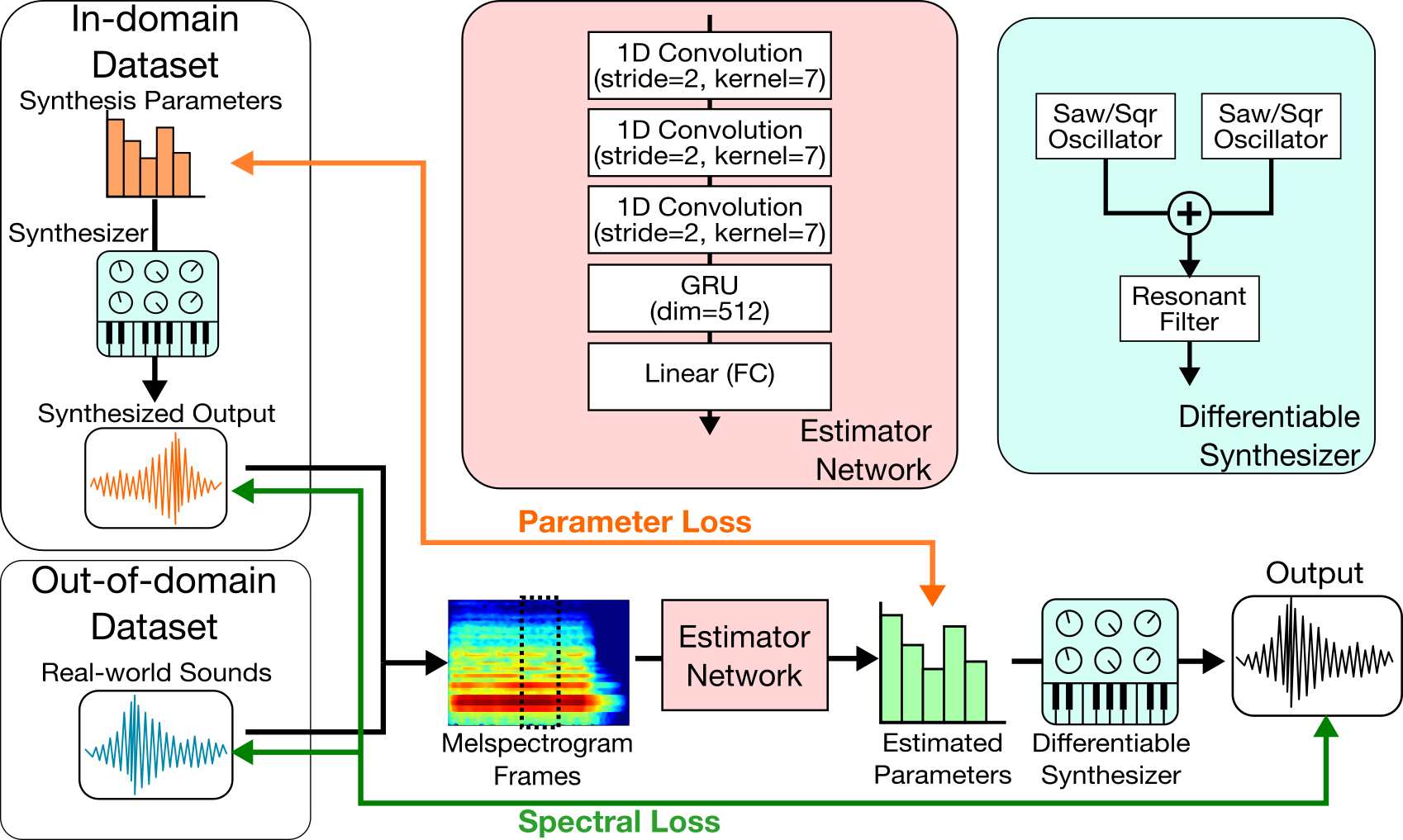
The proposed method implements a typical subtractive synthesizer using differentiable DSP modules. We can use this differentiable synthesizer during training to obtain a spectral loss of the actual synthesized sound and the target sound. We find that this is advantageous to using parameter loss for two reasons:
- The spectral loss is more directly related to the output of the system.
- We can train the network using out-of-domain (real-world) sounds, whose ground-truth synthesis parameters are unknown and cannot be trained using parameter loss.
Audio Examples
Comparison of the sound matches produced by 3 models: P-loss model (parameter loss only), Synth model (parameter+spectral loss, only in-domain data), and Real model (parameter+spectral loss, adapting to out-of-domain data). Subjective evaluation tests indicated that the Real model produced the best match for out-of-domain sounds.
| Out-of-domain Sounds | |||
|---|---|---|---|
| Target | P-loss | Synth | Real |
| In-domain Sounds | |||
|---|---|---|---|
| Target | P-loss | Synth | Real |
Extras
Direct Estimation of ADSR
By implementing a regular ADSR envelope in a differentiable manner, we can use an ADSR envelope model during training. The attack/decay/release times and sustain levels can be estimated for dynamic parameters.
Chorus Effector
A typical chorus/flanger effect is implemented by applying an LFO-modulated delay. The chorus mix and the delay size is estimated by the network.
| In-domain Sounds | |||
|---|---|---|---|
| Target | P-loss | Synth | |
M4L prototype (WIP)
Our ultimate goal is to create a synthesizer plugin which offers new interactive controls enabled by a deep learning model. The sound matching method can allow the users to use an existing sound as a starting point in the sound design process. Here is a short clip of our prototype model in action, implemented in Max for Live (with Node for Max and ONNX runtime for Node). It still has issues calculating envelope parameters (note off positions) correctly for diverse sounds.
Future work will focus on more powerful synthesizers with new DSP modules and new interactive applications besides sound matching.